
Anthropic’s own data puts code output per engineer at 200% growth after internal Claude Code deployment. Review throughput didn’t scale with it. PRs get skimmed, and the subtle logic errors, the removed auth guard, the field rename that breaks a query three files away, those slip through.
Claude Code Review’s answer is a multi-agent pipeline that dispatches specialized agents in parallel, runs a verification pass against each finding, and posts inline comments on the exact diff lines where it found problems. Anthropic prices this at $15-25 per review on average, on top of a Team or Enterprise plan seat.
This piece puts the tool through real PRs on a TypeScript tRPC codebase, surfaces the full output with confidence scores, shows what cleared the 80-point cutoff and what got filtered, and gives a clear take on cost. Where GitHub and the local plugin disagree, you see both.
🚀 Sign up for The Replay newsletter
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it’s your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
How the five-agent pipeline actually works
When a review kicks off, the pipeline moves through four phases in sequence. It starts with a Haiku agent that checks whether the PR qualifies and scans the repo for any CLAUDE.md files. Next, two agents run side by side, one summarizes the PR changes, the other pulls together the full diff. Then five specialized agents run in parallel on that diff. Finally, everything they flag goes through a verification pass before anything gets posted.
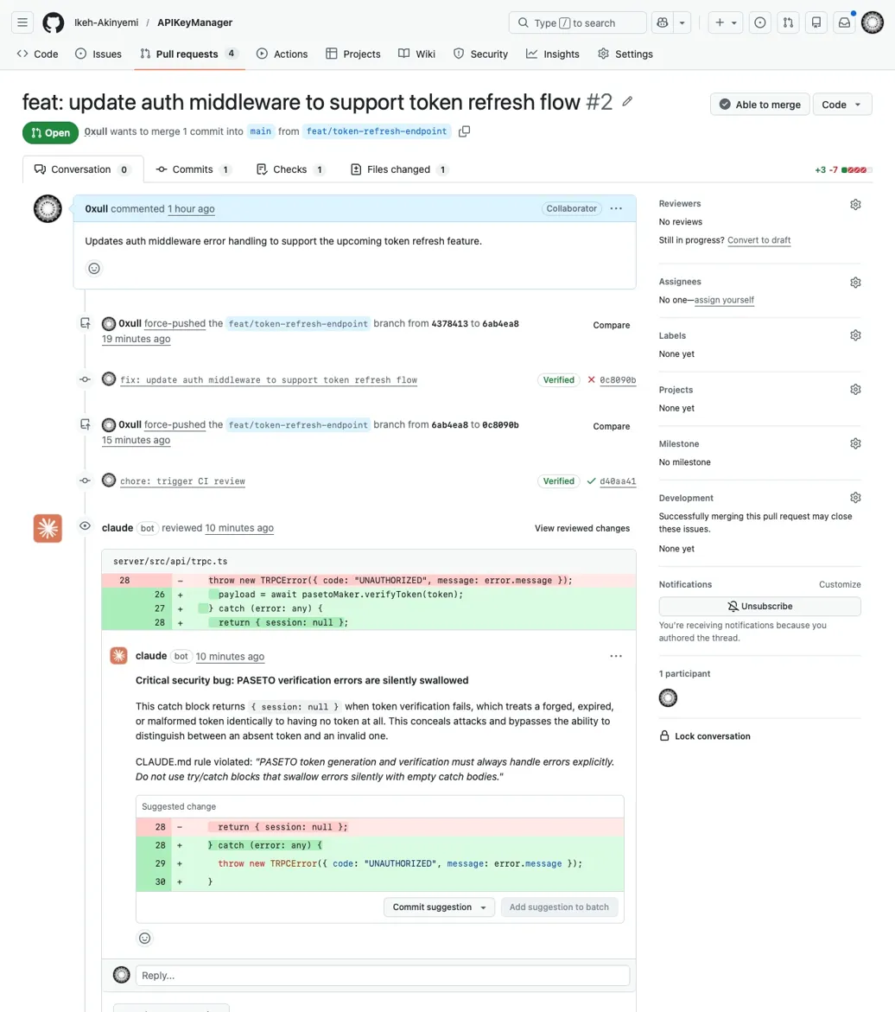
Those five agents each stick to a defined scope. Agent 1 checks CLAUDE.md compliance. Agent 2 does a shallow bug sweep. Agent 3 looks at git blame and history for context. Agent 4 reviews past PR comments to spot recurring patterns. Agent 5 checks whether code comments still line up with the code. Each one returns a list of issues with a confidence score from 0 to 100. The orchestrator then spins up scoring subagents for each finding, and anything under 80 gets dropped before posting. You can see that filter clearly in the local plugin output: in the PR #2 run, issue 1 came in at 75 and was filtered out, while issue 2 hit 100 and made it through.
The 80 threshold is the primary noise-reduction mechanism. An agent that flags a real issue but cannot verify it against the actual code drops below the cutoff. This is what the plugin source confirms: scoring subagents are spawned specifically to disprove each candidate finding, not just to restate it. A finding that survives that challenge at 80 or above is the only one that reaches the PR.
Testing setup and environment
The test repository is Ikeh-Akinyemi/APIKeyManager, a TypeScript tRPC API with PASETO token authentication, Sequelize ORM, and Zod input validation. Two files were added to the repository root before any PR was opened: CLAUDE.md , encoding explicit rules around error handling, token validation, and input schemas, and REVIEW.md, scoping what the review agents should prioritize and skip.
The REVIEW.md used across all test runs:
# Code Review Scope ## Always flag - Authentication middleware that does not validate token expiry - tRPC procedures missing Zod input validation - Sequelize multi-model mutations outside a transaction - Empty catch blocks that discard errors silently - express middleware that calls next() instead of next(err) on failure ## Flag as nit - CLAUDE.md naming or style violations in non-auth code - Missing .strict() on Zod schemas in low-risk read procedures ## Skip - node_modules/ - *.lock files - Migration files under db/migrations/ (generated, schema changes reviewed separately) - Test fixtures and seed data
Reviews were triggered in two ways. The Claude-code-action GitHub Actions workflow ran automatically on every PR push, authenticated using CLAUDE_CODE_OAUTH_TOKEN from a Claude Max subscription, and posted inline annotations straight onto the GitHub diff. In parallel, the local /code-review:code-review plugin, installed via /plugin code-review inside Claude Code, was run against the same PRs from the terminal. That surfaced what GitHub doesn’t show: per-agent token costs, confidence scores, and which findings got filtered out.
What it caught that actually mattered
Four PRs were opened against Ikeh-Akinyemi/APIKeyManager, each targeting a different agent in the pipeline. Three findings worth examining. The fourth, a clean JSDoc addition, returned no issues introduced by the changes made to the codebase.
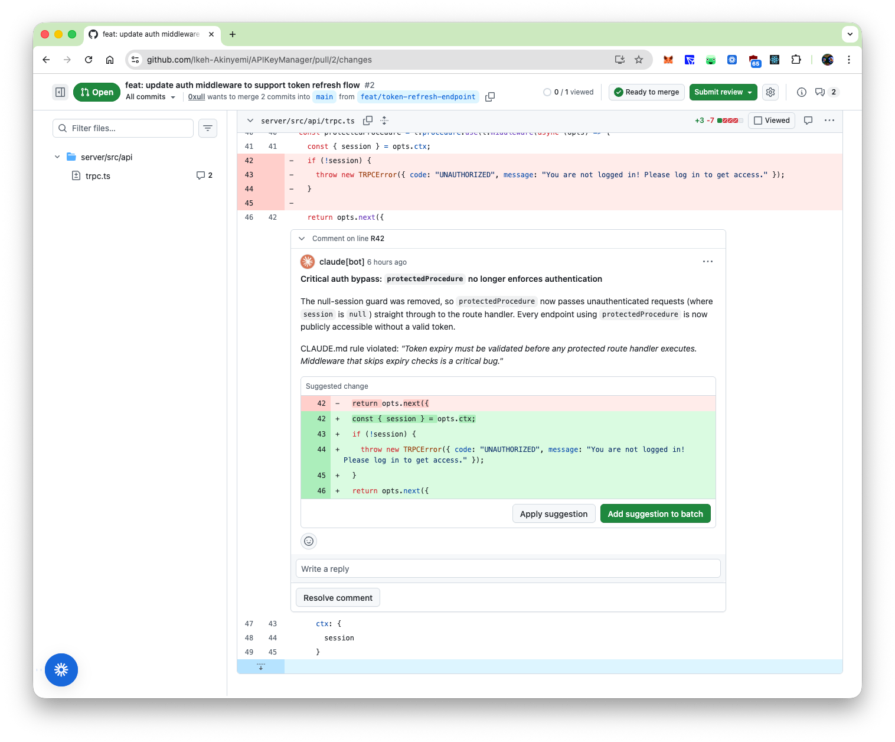
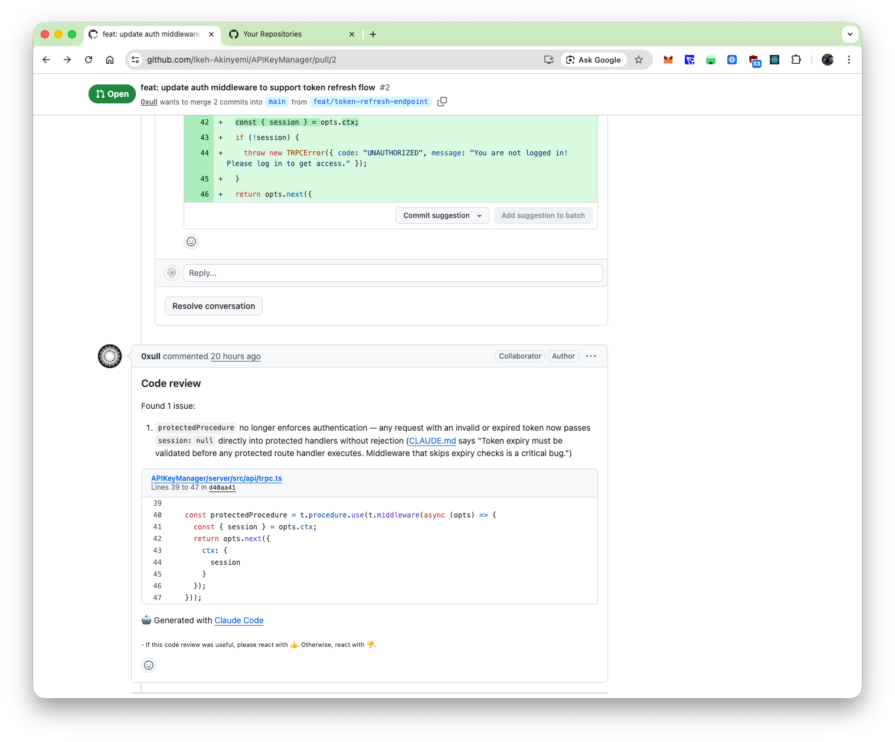
Finding 1: Auth bypass via removed session guard (PR #2, bug detection agent)
PR #2 removed a null-session guard from protectedProcedure in server/src/api/trpc.ts, framed in the commit message as token refresh support. The bug detection agent scored this at confidence 100, as seen in the earlier screenshot. The compliance agent scored the accompanying silent PASETO catch block at 75, which the filter dropped.
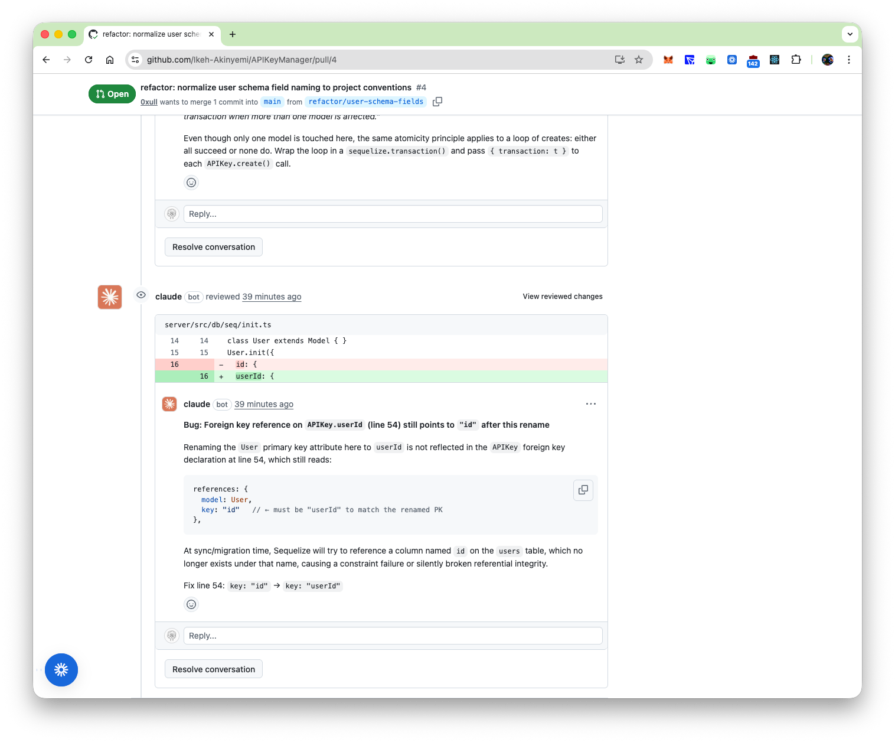
Finding 2: Cross-file regression from field rename (PR #4, full-codebase reasoning)
PR #4 renamed a field on the User model in one file. The changed file looks correct in isolation. But the pipeline flagged a stale reference in a separate file not included in the diff, a query still using the old field name.
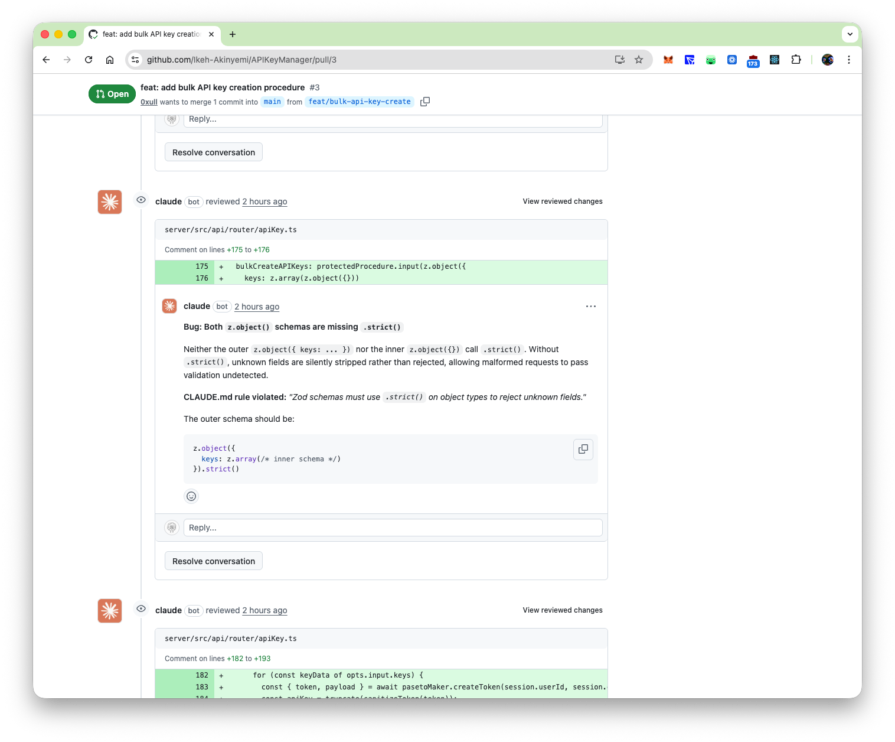
Finding 3: Missing Zod validation flagged by compliance agent (PR #3, Zod violation)
Amongst the reviews posted on PR #3, the compliance agent read CLAUDE.md, identified the rule requiring .strict() on all Zod object schemas, and flagged a tRPC procedure whose input schema used a plain z.object({}) without it.
The pipeline caught all three because it reads the surrounding codebase and your CLAUDE.md, not just what changed.
What it flagged that didn’t matter
Every finding that was posted was a real bug. But two output patterns created noise worth examining. The first was pre-existing bugs surfacing on unrelated PRs. PR #4 changed one line in server/src/db/seq/init.ts, renaming the User primary key from id to userId. The pipeline correctly caught the stale foreign key reference in a separate file, but also posted four additional findings against trpc.ts and apiKey.ts, none introduced by PR #4. At scale, with a codebase carrying accumulated debt, a PR touching one file that produces review comments against five others becomes its own kind of overhead.
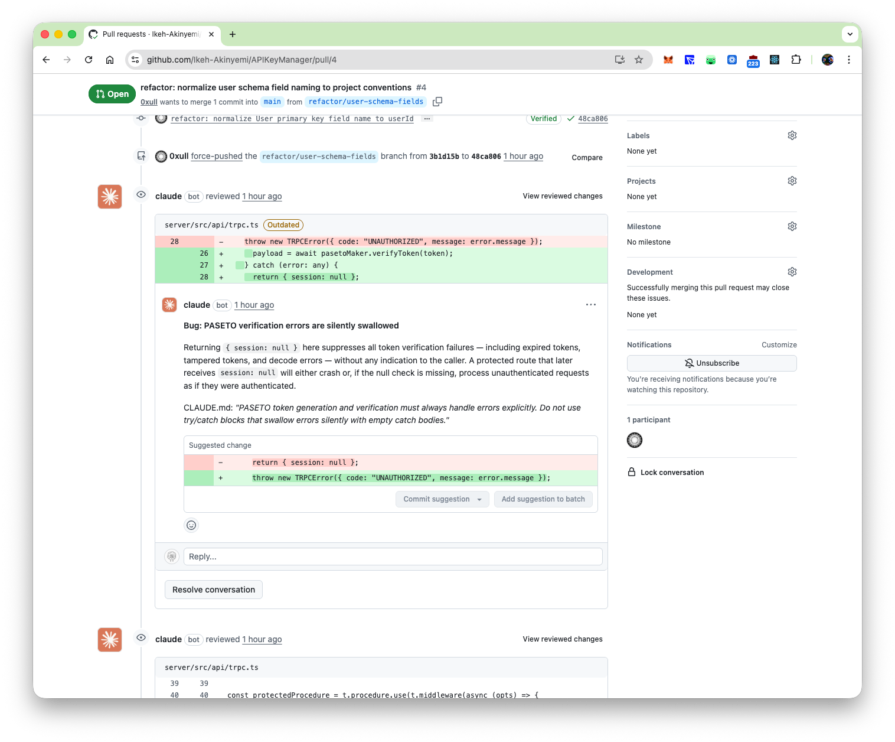
The second pattern is the threshold filter, making a judgment call. On PR #2, the PASETO silent swallow scored 75 and was filtered. The terminal output stated the reason: the null return appeared intentional for a token-refresh flow. The scoring subagent read the commit message, inferred intent, and docked confidence. This finding is a real bug, but whether that is noise suppression or information suppression depends on your team’s risk tolerance for the auth code. Dropping the threshold from 80 to 65 will surface it, along with everything else the filter was holding back.
Conclusion
The pipeline proved its value on the kind of PRs that look harmless but aren’t. A one-line field rename that quietly breaks a foreign key in a file outside the diff, an auth guard removed under the cover of a token-refresh change, a bulk loop with no transaction boundary. None of these stand out on a skim, and each one was flagged with enough context to fix on the spot.
The setup matters just as much as the tool. A CLAUDE.md that actually reflects your team’s correctness rules, a REVIEW.md that defines what should be flagged versus ignored, and a threshold tuned to your risk tolerance, that’s what separates signal from noise. The agents are there out of the box. Whether they’re useful depends on how you configure them.
PakarPBN
A Private Blog Network (PBN) is a collection of websites that are controlled by a single individual or organization and used primarily to build backlinks to a “money site” in order to influence its ranking in search engines such as Google. The core idea behind a PBN is based on the importance of backlinks in Google’s ranking algorithm. Since Google views backlinks as signals of authority and trust, some website owners attempt to artificially create these signals through a controlled network of sites.
In a typical PBN setup, the owner acquires expired or aged domains that already have existing authority, backlinks, and history. These domains are rebuilt with new content and hosted separately, often using different IP addresses, hosting providers, themes, and ownership details to make them appear unrelated. Within the content published on these sites, links are strategically placed that point to the main website the owner wants to rank higher. By doing this, the owner attempts to pass link equity (also known as “link juice”) from the PBN sites to the target website.
The purpose of a PBN is to give the impression that the target website is naturally earning links from multiple independent sources. If done effectively, this can temporarily improve keyword rankings, increase organic visibility, and drive more traffic from search results.